Word embeddings in Sentiment Analysis
Understanding how does word embedding work in a sentiment analysis model.
 Image credit: zamani.ai
Image credit: zamani.ai
Word embedding
In the sentiment analysis task, we can use either a trainable word embedding or a pretrained one. A pretrained word embedding such as Word2Vec or Glove has trained to capture semantic relationship between two words. It means if they are semantically close together, their word embedding vector is also similar (based on similarity measurement such as cosine similarity). So, this is expected to be helpful in a sentiment analysis task as we expect the similar words to have the same sentiment.
On the other hand, the trainable word embedding (or embedding layer) could be trained based on specific task e.g. sentiment analysis. Despite the pretrained word embedding, the trainable word embedding representation is randomly initialized at the begining of learning sentiment analysis. Then, eventually, the vectors are updated to organize the words sentimentally.
Visualization
The goal is to show that how a trainable word embedding is updated during the training process of sentiment analysis task. The embedding dimension is chosen as 2. Therefore, we can directly observe the changes in the word embedding without using any dimension reduction approach such t-SNE. The values of word embedding are averaged out to summarize every given sentence with a fixed 2 dimension.Then, it is connected to a 5 layer MLP (Fully connected). The number of layers are selected without any extensive hyper-parameter search.
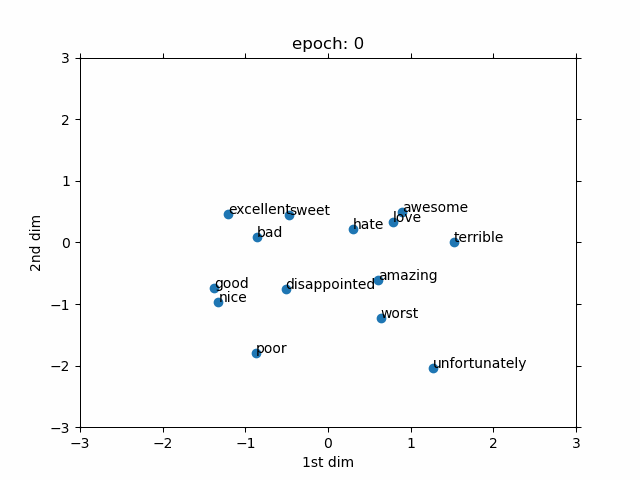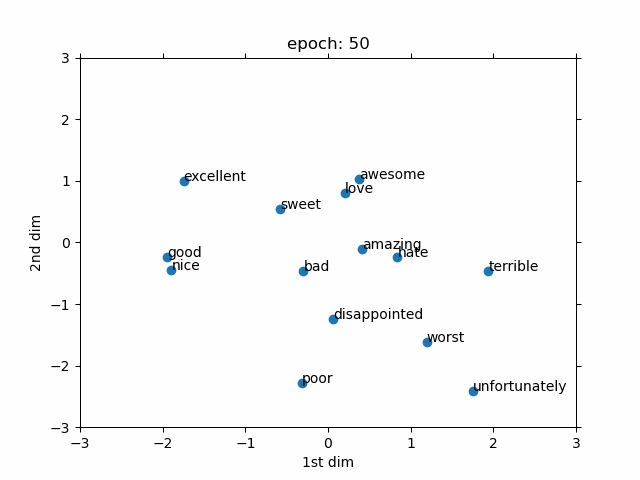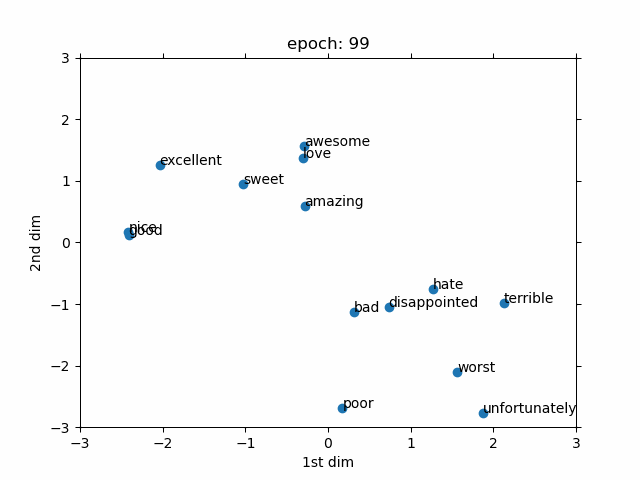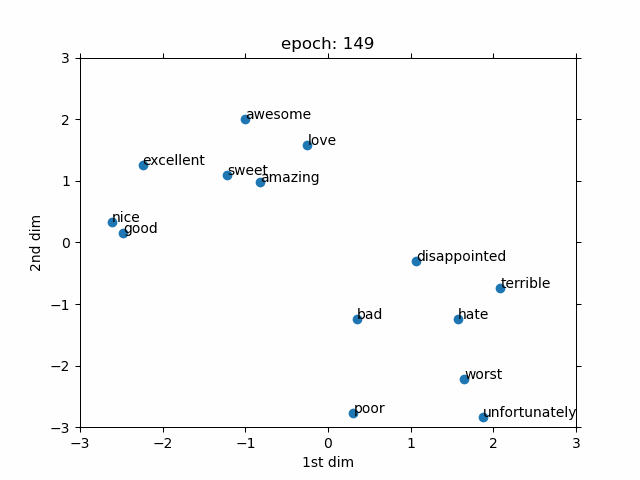
Only few interesting words are selected to be observed during training. As can be seen, at the beginning (i.e. epoch 1), every word is randomly placed due to the random initialization. However, eventually, the positive words move to the one side of the graph and the negative words move to the other side. After, some epochs the selected words are linearly separable which makes the job for the deep learning part much easier. Although, it should be considered that the demo is only for a selected group of words.
Mohammad Ali Zamani
Senior Machine Learning Applied Scientist
I am a Senior Machine Learning Applied Scientist at Hamburg Informatics Technology Center (HITeC) and a Research Associate at University of Hamburg. My research interests include Deep Reinforcement Learning, Computer Vision, Cognitive Robotics and Natural Language Processing.