Abstract
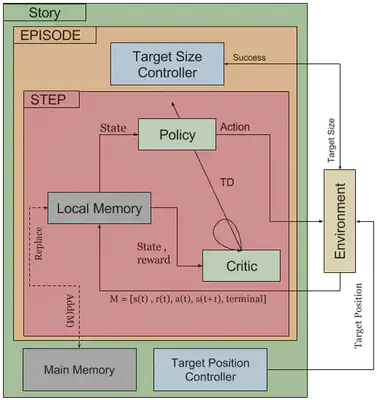
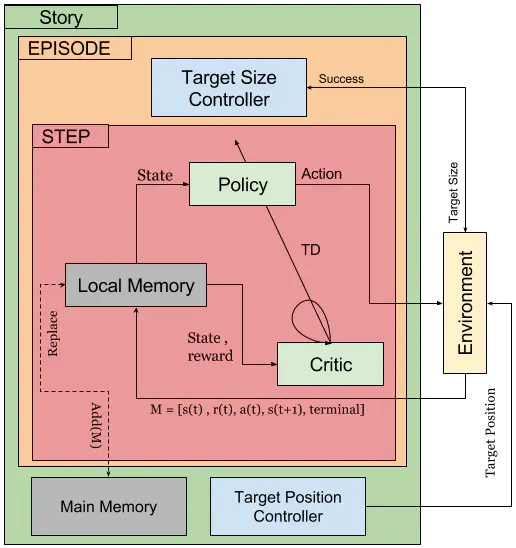
Robotic motor policies can, in theory, be learned via deep continuous reinforcement learning. In practice, however, collecting the enormous amount of required training samples in realistic time, surpasses the possibilities of many robotic platforms. To address this problem, we propose a novel method for accelerating the learning process by task simplification inspired by the Goldilocks effect known from developmental psychology. We present results on a reachfor-grasp task that is learned with the Deep Deterministic Policy Gradients (DDPG) algorithm. Task simplification is realized by initially training the system with “larger-thanlife” training objects that adapt their reachability dynamically during training. We achieve a significant acceleration compared to the unaltered training setup. We describe modifications to the DDPG algorithm with regard to the replay buffer to prevent artifacts during the learning process from the simplified learning instances while maintaining the speed of learning. With this result, we contribute towards the realistic application of deep reinforcement learning on robotic platforms.